I normally use the Money data type when designing databases , as I've always read that it was specifically designed for currencies. One of the advantages , for example , is that you can use a currency symbol with it. Recently I came across something very interesting while browsing the net. Apparently there are accuracy issues with the data type. I have below a simple example to demonstrate. Note that this isn't my example but something that I found on the web which I thought I'd share :
declare @m money
declare @d decimal(9,2)
set @m = 19.34
set @d = 19.34
select (@m/1000)*1000
select (@d/1000)*1000
So what would the results be ? Well if you're expecting 19.34 for the money variable , you'd be wrong !! You actually get 19.30. Yup, I was surprised as you are right now. I've even tested this in the Katmai CTP and it does the same thing. So from now on I'll try to use decimal and specify the precision I need , when creating tables.
Friday, September 18, 2009
Thursday, September 17, 2009
How to configure drill through reports open in a new window in SSRS 2005
When using the standard Reporting Services drill-through navigation the new report is rendered in the current browser window, therefore overlaying the original report. There is no built in way to indicate you want the drill-through report to open a new window. In a standard web browser you can use the (shift-click) functionality to open the link in a new window, but in Reporting Services this functionality is disabled. So how can you launch a new window when you open a drill-through report?
Solution
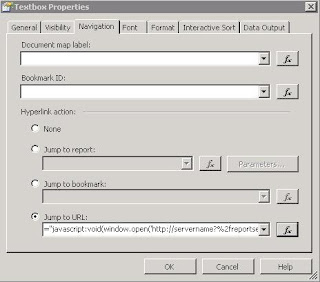
Use a little javascript with a customized URL in the "Jump to URL" option of the Navigation tab.
Non-parameterized Solution
To get started, let's pop up a simple non parameterized report. Follow these instructions:
1. Instead of using the "Jump to Report" option on the Navigation tab, use the "Jump to URL" option.
2. Open the expression screen (Fx button).
3. Enter the following:
--------------------------------------------------------------------------------
="javascript:void(window.open('http://servername?%2freportserver%2fpathto%2freport&rs:Command=Render'))"
--------------------------------------------------------------------------------
4. Click OK twice, then save and deploy the report.
Note: The link will not work from the designer environment. You must deploy the report (hopefully to a test area) to try the link.
See screenshots below.

Parameterized Solution
Now, let's say you want to pass a variable to the drill through report. Let's also assume you have a field called ProductCode. Normally, you might hard code that like this:
http://servername/reportserver?%2fpathto%2freport&rs:Command=Render&ProductCode=123
In this case, you want to pass variables dynamically, using an available value from the source dataset.
You can think of it like this:
http://servername/reportserver?%2fpathto%2freport&rs:Command=Render&ProductCode=Fields!ProductCode.Value
The exact syntax in the "Jump to URL" (Fx) expression window will be:
--------------------------------------------------------------------------------
="javascript:void(window.open('http://servername/reportserver?%2fpathto%2freport&rs:Command=Render&ProductCode="+Fields!ProductCode.Value+"'))"
--------------------------------------------------------------------------------
Note - To avoid confusion between double and single quotes, double quotes are in red above.
Notice, that the static portion of the URL is delimited within double quotes.
Solution
Use a little javascript with a customized URL in the "Jump to URL" option of the Navigation tab.
Non-parameterized Solution
To get started, let's pop up a simple non parameterized report. Follow these instructions:
1. Instead of using the "Jump to Report" option on the Navigation tab, use the "Jump to URL" option.
2. Open the expression screen (Fx button).
3. Enter the following:
--------------------------------------------------------------------------------
="javascript:void(window.open('http://servername?%2freportserver%2fpathto%2freport&rs:Command=Render'))"
--------------------------------------------------------------------------------
4. Click OK twice, then save and deploy the report.
Note: The link will not work from the designer environment. You must deploy the report (hopefully to a test area) to try the link.
See screenshots below.


Parameterized Solution
Now, let's say you want to pass a variable to the drill through report. Let's also assume you have a field called ProductCode. Normally, you might hard code that like this:
http://servername/reportserver?%2fpathto%2freport&rs:Command=Render&ProductCode=123
In this case, you want to pass variables dynamically, using an available value from the source dataset.
You can think of it like this:
http://servername/reportserver?%2fpathto%2freport&rs:Command=Render&ProductCode=Fields!ProductCode.Value
The exact syntax in the "Jump to URL" (Fx) expression window will be:
--------------------------------------------------------------------------------
="javascript:void(window.open('http://servername/reportserver?%2fpathto%2freport&rs:Command=Render&ProductCode="+Fields!ProductCode.Value+"'))"
--------------------------------------------------------------------------------
Note - To avoid confusion between double and single quotes, double quotes are in red above.
Notice, that the static portion of the URL is delimited within double quotes.
Friday, April 24, 2009
Versions of SQL Server 2005 Available
Versions of SQL Server 2005 Available
Microsoft recognizes that there is a plethora of database users with disparate needs. They therefore have released the following six versions of SQL Server 2005:
SQL Server 2005 Express Edition
SQL Server 2005 Workgroup Edition
SQL Server 2005 Developer Edition
SQL Server 2005 Standard Edition
SQL Server 2005 Enterprise Edition
SQL Server 2005 Mobile Edition
SQL Server 2005 Express Edition
SQL Server 2005 Express provides a great means of getting started with SQL Server. It offers a robust, reliable, stable environment that is free and easy to use. It provides the same protection and information management provided by the more sophisticated versions of SQL Server. Other advantages of SQL Server Express include
Easy installation
Lightweight management and query editing tool
Support for Windows authentication
"Secure by Default" settings
Royalty-free distribution
Rich database functionality, including triggers, stored procedures, functions, extended indexes, and Transact-SQL support
XML Support
Deep integration with Visual Studio 2005
SQL Server 2005 Express has a few disadvantages that make it unusable in many situations. These include
Support for only one gigabyte of RAM
Support for a four-gigabyte maximum database size
Support for only one CPU
Absence of the SQL Agent Job Scheduling Service
Absence of the Database Tuning Advisor
SQL Server 2005 Workgroup Edition
SQL Server Workgroup Edition provides a great solution for small organizations or workgroups within larger entities. It includes a rich feature set, but is affordable and simple to work with. Other valuable features include the fact that there is no limit on database size and that it supports the SQL Agent Job Scheduling Service. The disadvantages of SQL Server 2005 Workgroup Edition include
Support for only three gigabytes of RAM
Support for only two CPUs
Absence of the Database Tuning Advisor
SQL Server 2005 Developer Edition
SQL Server 2005 Developer Edition is designed specifically for developers who are building SQL Server 2005 applications. It includes all functionality of SQL Server 2005 Enterprise Edition, but with a special license that limits its use to development and testing. Its license specifies that you cannot use it for production development. For more details about the features of SQL Server 2005 Developer Edition, see the section "SQL Server 2005 Enterprise Edition" later in this section.
SQL Server 2005 Standard Edition
SQL Server Standard Edition provides an affordable option for small- and medium-sized businesses. It includes all functionality required for non-critical e-commerce, data warehousing, and line-of-business solutions. The advantages of SQL Server 2005 Standard Edition include
RAM limited solely by operating system RAM
No limit for database size
Full 64-bit support
Database mirroring
Failover clustering
Inclusion of the Database Tuning Advisor
Inclusion of the full-featured Management Studio
Inclusion of the Profiler
Inclusion of the SQL Agent Job Scheduling Service
The disadvantages of SQL Server 2005 Standard Edition include
Support for only four CPUs
No support for online indexing
No support online restore
No support for fast recovery
SQL Server 2005 Enterprise Edition
SQL Server 2005 Enterprise Edition includes all the tools that you need to manage an enterprise database management system. It offers a complete set of enterprise management and business intelligence features, and provides the highest levels of scalability and availability of all the SQL Server 2005 editions. It supports an unlimited number of CPUs and provides all the features unavailable in the other versions of SQL Server 2005.
SQL Server 2005 Mobile Edition
SQL Server 2005 Mobile Edition enables you to easily port corporate applications over to mobile devices. SQL Server 2005 Mobile Edition offers many advantages. They include
Inclusion of SQL Workbench (a tool that replaces SQL Server 2005 Management Studio)
Full integration with SQL Server 2005
Inclusion of synchronization functionality
Excellent reliability and performance due to a revamped storage engine and an improved query processor
Multi-user support via multi-user synchronization and row-level locking
Full integration with Visual Studio 2005
Increased device support
Microsoft recognizes that there is a plethora of database users with disparate needs. They therefore have released the following six versions of SQL Server 2005:
SQL Server 2005 Express Edition
SQL Server 2005 Workgroup Edition
SQL Server 2005 Developer Edition
SQL Server 2005 Standard Edition
SQL Server 2005 Enterprise Edition
SQL Server 2005 Mobile Edition
SQL Server 2005 Express Edition
SQL Server 2005 Express provides a great means of getting started with SQL Server. It offers a robust, reliable, stable environment that is free and easy to use. It provides the same protection and information management provided by the more sophisticated versions of SQL Server. Other advantages of SQL Server Express include
Easy installation
Lightweight management and query editing tool
Support for Windows authentication
"Secure by Default" settings
Royalty-free distribution
Rich database functionality, including triggers, stored procedures, functions, extended indexes, and Transact-SQL support
XML Support
Deep integration with Visual Studio 2005
SQL Server 2005 Express has a few disadvantages that make it unusable in many situations. These include
Support for only one gigabyte of RAM
Support for a four-gigabyte maximum database size
Support for only one CPU
Absence of the SQL Agent Job Scheduling Service
Absence of the Database Tuning Advisor
SQL Server 2005 Workgroup Edition
SQL Server Workgroup Edition provides a great solution for small organizations or workgroups within larger entities. It includes a rich feature set, but is affordable and simple to work with. Other valuable features include the fact that there is no limit on database size and that it supports the SQL Agent Job Scheduling Service. The disadvantages of SQL Server 2005 Workgroup Edition include
Support for only three gigabytes of RAM
Support for only two CPUs
Absence of the Database Tuning Advisor
SQL Server 2005 Developer Edition
SQL Server 2005 Developer Edition is designed specifically for developers who are building SQL Server 2005 applications. It includes all functionality of SQL Server 2005 Enterprise Edition, but with a special license that limits its use to development and testing. Its license specifies that you cannot use it for production development. For more details about the features of SQL Server 2005 Developer Edition, see the section "SQL Server 2005 Enterprise Edition" later in this section.
SQL Server 2005 Standard Edition
SQL Server Standard Edition provides an affordable option for small- and medium-sized businesses. It includes all functionality required for non-critical e-commerce, data warehousing, and line-of-business solutions. The advantages of SQL Server 2005 Standard Edition include
RAM limited solely by operating system RAM
No limit for database size
Full 64-bit support
Database mirroring
Failover clustering
Inclusion of the Database Tuning Advisor
Inclusion of the full-featured Management Studio
Inclusion of the Profiler
Inclusion of the SQL Agent Job Scheduling Service
The disadvantages of SQL Server 2005 Standard Edition include
Support for only four CPUs
No support for online indexing
No support online restore
No support for fast recovery
SQL Server 2005 Enterprise Edition
SQL Server 2005 Enterprise Edition includes all the tools that you need to manage an enterprise database management system. It offers a complete set of enterprise management and business intelligence features, and provides the highest levels of scalability and availability of all the SQL Server 2005 editions. It supports an unlimited number of CPUs and provides all the features unavailable in the other versions of SQL Server 2005.
SQL Server 2005 Mobile Edition
SQL Server 2005 Mobile Edition enables you to easily port corporate applications over to mobile devices. SQL Server 2005 Mobile Edition offers many advantages. They include
Inclusion of SQL Workbench (a tool that replaces SQL Server 2005 Management Studio)
Full integration with SQL Server 2005
Inclusion of synchronization functionality
Excellent reliability and performance due to a revamped storage engine and an improved query processor
Multi-user support via multi-user synchronization and row-level locking
Full integration with Visual Studio 2005
Increased device support
Learn More About Constraints
Microsoft SQL Server Constraints
Using Microsoft's SQL Server CHECK, DEFAULT, NULL, and UNIQUE constraints to maintain database Domain, Referential, and Entity integrity
**************************************************************
The primary job of a constraint is to enforce a rule in the database. Together, the constraints in a database maintain the integrity of the database. For instance, we have foreign key constraints to ensure all orders reference existing products. You cannot enter an order for a product the database does not know about. Maintaining integrity is of utmost importance for a database, so much so that we cannot trust users and applications to enforce these rules by themselves. Once integrity is lost, you may find customers are double billed, payments to the supplier are missing, and everyone loses faith in your application. We will be talking in the context of the SQL Server sample Northwind database.
Data integrity rules fall into one of three categories: entity, referential, and domain. We want to briefly describe these terms to provide a complete discussion.
Entity Integrity
Entity integrity ensures each row in a table is a uniquely identifiable entity. You can apply entity integrity to a table by specifying a PRIMARY KEY constraint. For example, the ProductID column of the Products table is a primary key for the table.
Referential Integrity
Referential integrity ensures the relationships between tables remain preserved as data is inserted, deleted, and modified. You can apply referential integrity using a FOREIGN KEY constraint. The ProductID column of the Order Details table has a foreign key constraint applied referencing the Orders table. The constraint prevents an Order Detail record from using a ProductID that does not exist in the database. Also, you cannot remove a row from the Products table if an order detail references the ProductID of the row.
Entity and referential integrity together form key integrity.
Domain Integrity
Domain integrity ensures the data values inside a database follow defined rules for values, range, and format. A database can enforce these rules using a variety of techniques, including CHECK constraints, UNIQUE constraints, and DEFAULT constraints. These are the constraints we will cover in this article, but be aware there are other options available to enforce domain integrity. Even the selection of the data type for a column enforces domain integrity to some extent. For instance, the selection of datetime for a column data type is more restrictive than a free format varchar field.
The following list gives a sampling of domain integrity constraints.
A product name cannot be NULL.
A product name must be unique.
The date of an order must not be in the future.
The product quantity in an order must be greater than zero.
Unique Constraints
As we have already discussed, a unique constraint uses an index to ensure a column (or set of columns) contains no duplicate values. By creating a unique constraint, instead of just a unique index, you are telling the database you really want to enforce a rule, and are not just providing an index for query optimization. The database will not allow someone to drop the index without first dropping the constraint.
From a SQL point of view, there are three methods available to add a unique constraint to a table. The first method is to create the constraint inside of CREATE TABLE as a column constraint. A column constraint applies to only a single column. The following SQL will create a unique constraint on a new table: Products_2.
CREATE TABLE Products_2
(
ProductID int PRIMARY KEY,
ProductName nvarchar (40) Constraint IX_ProductName UNIQUE
)
This command will actually create two unique indexes. One is the unique, clustered index given by default to the primary key of a table. The second is the unique index using the ProductName column as a key and enforcing our constraint.
A different syntax allows you to create a table constraint. Unlike a column constraint, a table constraint is able to enforce a rule across multiple columns. A table constraint is a separate element in the CREATE TABLE command. We will see an example of using multiple columns when we build a special CHECK constraint later in the article. Notice there is now a comma after the ProductName column definition.
CREATE TABLE Products_2
(
ProductID int PRIMARY KEY,
ProductName nvarchar (40),
CONSTRAINT IX_ProductName UNIQUE(ProductName)
)
The final way to create a constraint via SQL is to add a constraint to an existing table using the ALTER TABLE command, as shown in the following command:
CREATE TABLE Products_2
(
ProductID int PRIMARY KEY,
ProductName nvarchar (40)
)
ALTER TABLE Products_2
ADD CONSTRAINT IX_ProductName UNIQUE (ProductName)
If duplicate data values exist in the table when the ALTER TABLE command runs, you can expect an error message similr to the following:
Server: Msg 1505, Level 16, State 1, Line 1
CREATE UNIQUE INDEX terminated because a duplicate key was found for index ID 2.
Most significant primary key is 'Hamburger'.
Server: Msg 1750, Level 16, State 1, Line 1
Could not create constraint. See previous errors.
The statement has been terminated.
Check Constraints
Check constraints contain an expression the database will evaluate when you modify or insert a row. If the expression evaluates to false, the database will not save the row. Building a check constraint is similar to building a WHERE clause. You can use many of the same operators (>, <, <=, >=, <>, =) in additional to BETWEEN, IN, LIKE, and NULL. You can also build expressions around AND and OR operators. You can use check constraints to implement business rules, and tighten down the allowed values and formats allowed for a particular column.
We can use the same three techniques we learned earlier to create a check constraint using SQL. The first technique places the constraint after the column definition, as shown below. Note the constraint name is optional for unique and check constraints.
CREATE TABLE Products_2
(
ProductID int PRIMARY KEY,
UnitPrice money CHECK(UnitPrice > 0 AND UnitPrice < 100)
)
In the above example we are restricting values in the UnitPrice column between 0 and 100. Let’s try to insert a value outside of this range with the following SQL.
INSERT INTO Products_2 VALUES(1, 101)
The database will not save the values and should respond with the following error.
Server: Msg 547, Level 16, State 1, Line 1
INSERT statement conflicted with COLUMN CHECK constraint 'CK__Products___UnitP__2739D489'.
The conflict occurred in database 'Northwind', table 'Products_2', column 'UnitPrice'.
The statement has been terminated.
The following sample creates the constraint as a table constraint, separate from the column definitions.
CREATE TABLE Products_2
(
ProductID int PRIMARY KEY,
UnitPrice money,
CONSTRAINT CK_UnitPrice2 CHECK(UnitPrice > 0 AND UnitPrice < 100)
)
Remember, with a table constraint you can reference multiple columns. The constraint in the following example will ensure we have either a telephone number or a fax number for every customer.
CREATE TABLE Customers_2
(
CustomerID int,
Phone varchar(24),
Fax varchar(24),
CONSTRAINT CK_PhoneOrFax
CHECK(Fax IS NOT NULL OR PHONE IS NOT NULL)
)
You can also add check constraints to a table after a table exists using the ALTER TABLE syntax. The following constraint will ensure an employee date of hire is always in the past by using the system function GETTIME.
CREATE TABLE Employees_2
(
EmployeeID int,
HireDate datetime
)
ALTER TABLE Employees_2
ADD CONSTRAINT CK_HireDate CHECK(hiredate < GETDATE())
Check Constraints and Existing Values
As with UNIQUE constraints, adding a CHECK constraint after a table is populated runs a chance of failure, because the database will check existing data for conformance. This is not optional behavior with a unique constraint, but it is possible to avoid the conformance test when adding a CHECK constraint using WITH NOCHECK syntax in SQL.
CREATE TABLE Employees_2
(
EmployeeID int,
Salary money
)
INSERT INTO Employees_2 VALUES(1, -1)
ALTER TABLE Employees_2 WITH NOCHECK
ADD CONSTRAINT CK_Salary CHECK(Salary > 0)
Check Constraints and NULL Values
Earlier in this section we mentioned how the database will only stop a data modification when a check restraint returns false. We did not mention, however, how the database allows the modification to take place if the result is logically unknown. A logically unknown expression happens when a NULL value is present in an expression. For example, let’s use the following insert statement on the last table created above.
INSERT INTO Employees_2 (EmployeeID, Salary) VALUES(2, NULL)
Even with the constraint on salary (Salary > 0) in place, the INSERT is successful. A NULL value makes the expression logically unknown. A CHECK constraint will only fail an INSERT or UPDATE if the expression in the constraint explicitly returns false. An expression returning true, or a logically unknown expression will let the command succeed.
Restrictions On Check Constraints
Although check constraints are by far the easiest way to enforce domain integrity in a database, they do have some limitations, namely:
A check constraint cannot reference a different row in a table.
A check constraint cannot reference a column in a different table.
NULL Constraints
Although not a constraint in the strictest definition, the decision to allow NULL values in a column or not is a type of rule enforcement for domain integrity.
Using SQL you can use NULL or NOT NULL on a column definition to explicitly set the nullability of a column. In the following example table, the FirstName column will accept NULL values while LastName always requires a non NULL value. Primary key columns require a NOT NULL setting, and default to this setting if not specified.
CREATE TABLE Employees_2
(
EmployeeID int PRIMARY KEY,
FirstName varchar(50) NULL,
LastName varchar(50) NOT NULL,
)
If you do not explicitly set a column to allow or disallow NULL values, the database uses a number of rules to determine the "nullability" of the column, including current configuration settings on the server. I recommended you always define a column explicitly as NULL or NOT NULL in your scripts to avoid problems when moving between different server environments.
Given the above table definition, the following two INSERT statements can succeed.
INSERT INTO Employees_2 VALUES(1, 'Geddy', 'Lee')
INSERT INTO Employees_2 VALUES(2, NULL, 'Lifeson')
However, the following INSERT statement should fail with the error shown below.
INSERT INTO Employees_2 VALUES(3, 'Neil', NULL)
Server: Msg 515, Level 16, State 2, Line 1
Cannot insert the value NULL into column 'LastName', table 'Northwind.dbo.Employees_2';
column does not allow nulls. INSERT fails.
The statement has been terminated.
You can declare columns in a unique constraint to allow NULL values. However, the constraint checking considers NULL values as equal, so on a single column unique constraint, the database allows only one row to have a NULL value.
Default Constraints
Default constraints apply a value to a column when an INSERT statement does not specify the value for the column. Although default constraints do not enforce a rule like the other constraints we have seen, they do provide the proper values to keep domain integrity in tact. A default can assign a constant value, the value of a system function, or NULL to a column. You can use a default on any column except IDENTITY columns and columns of type timestamp.
The following example demonstrates how to place the default value inline with the column definition. We also mix in some of the other constraints we have seen in this article to show you how you can put everything together.
CREATE TABLE Orders_2
(
OrderID int IDENTITY NOT NULL ,
EmployeeID int NOT NULL ,
OrderDate datetime NULL DEFAULT(GETDATE()),
Freight money NULL DEFAULT (0) CHECK(Freight >= 0),
ShipAddress nvarchar (60) NULL DEFAULT('NO SHIPPING ADDRESS'),
EnteredBy nvarchar (60) NOT NULL DEFAULT(SUSER_SNAME())
)
We can examine the behavior of the defaults with the following INSERT statement, placing values only in the EmployeeID and Frieght fields.
INSERT INTO Orders_2 (EmployeeID, Freight) VALUES(1, NULL)
If we then query the table to see the row we just inserted, we should see the following results.
OrderID:1
EmployeeID:1
OrderDate:2003-01-02
Freight: NULL
ShipAddress: NO SHIPPING ADDRESS
EnteredBy: sa
Notice the Freight column did not receive the default value of 0. Specifying a NULL value is not the equivalent of leaving the column value unspecified, the database does not use the default and NULL is placed in the column instead.
Maintaining Constraints
In this section we will examine how to delete an existing constraint. We will also take a look at a special capability to temporarily disable constraints for special processing scenarios.
Dropping Constraints
First, let’s remove the check on UnitPrice in Product table.
ALTER TABLE Products
DROP CONSTRAINT CK_Products_UnitPrice
If all you need to do is drop a constraint to allow a one time circumvention of the rules enforcement, a better solution is to temporarily disable the constraint, as we explain in the next section.
Disabling Constraints
Special situations often arise in database development where it is convenient to temporarily relax the rules. For example, it is often easier to load initial values into a database one table at a time, without worrying with foreign key constraints and checks until all of the tables have finished loading. After the import is complete, you can turn constraint checking back on and know the database is once again protecting the integrity of the data.
Note: The only constraints you can disable are the FOREIGN KEY constraint, and the CHECK constraint. PRIMARY KEY, UNIQUE, and DEFAULT constraints are always active.
Disabling a constraint using SQL is done through the ALTER TABLE command. The following statements disable the CHECK constraint on the UnitsOnOrder column, and the FOREIGN KEY constraint on the CategoryID column.
ALTER TABLE Products NOCHECK CONSTRAINT CK_UnitsOnOrder
ALTER TABLE Products NOCHECK CONSTRAINT FK_Products_Categories
If you need to disable all of the constraints on a table, manually navigating through the interface or writing a SQL command for each constraint may prove to be a laborious process. There is an easy alternative using the ALL keyword, as shown below:
ALTER TABLE Products NOCHECK CONSTRAINT ALL
You can re-enable just the CK_UnitsOnOrder constraint again with the following statement:
ALTER TABLE Products CHECK CONSTRAINT CK_UnitsOnOrder
When a disabled constraint is re-enabled, the database does not check to ensure any of the existing data meets the constraints. We will touch on this subject shortly. To turn on all constraints for the Products table, use the following command:
ALTER TABLE Products CHECK CONSTRAINT ALL
Manually Checking Constaints
With the ability to disable and re-enable constraints, and the ability to add constraints to a table using the WITH NOCHECK option, you can certainly run into a condition where the referential or domain integrity of your database is compromised. For example, let’s imagine we ran the following INSERT statement after disabling the CK_UnitsOnOrder constraint:
INSERT INTO Products (ProductName, UnitsOnOrder) VALUES('Scott''s Stuffed Shells', -1)
The above insert statement inserts a -1 into the UnitsOnOrder column, a clear violation of the CHECK constraint in place on the column. When we re-enable the constraint, SQL Server will not complain as the data is not checked. Fortunately, SQL Server provides a Database Console Command you can run from any query tool to check all enabled constraints in a database or table. With CK_UnitsOnOrder re-enabled, we can use the following command to check for constraint violations in the Products table.
dbcc checkconstraints(Products)
To check an entire database, omit the parentheses and parameter from the DBCC command. The above command will give the following output and find the violated constraint in the Products table.
Table Constraint Where
Products CK_UnitsOnOrder UnitsOnOrder = '-1'
You can use the information in the DBCC output to track down the offending row.
---Summary------ ---------------- --------------------
Through article we learned how to use various constraints to ensure the data in our database stays intact and matches our expectations. The proper use of constrains is the prevention needed to avoid data integrity problems as your application grows.
Using Microsoft's SQL Server CHECK, DEFAULT, NULL, and UNIQUE constraints to maintain database Domain, Referential, and Entity integrity
**************************************************************
The primary job of a constraint is to enforce a rule in the database. Together, the constraints in a database maintain the integrity of the database. For instance, we have foreign key constraints to ensure all orders reference existing products. You cannot enter an order for a product the database does not know about. Maintaining integrity is of utmost importance for a database, so much so that we cannot trust users and applications to enforce these rules by themselves. Once integrity is lost, you may find customers are double billed, payments to the supplier are missing, and everyone loses faith in your application. We will be talking in the context of the SQL Server sample Northwind database.
Data integrity rules fall into one of three categories: entity, referential, and domain. We want to briefly describe these terms to provide a complete discussion.
Entity Integrity
Entity integrity ensures each row in a table is a uniquely identifiable entity. You can apply entity integrity to a table by specifying a PRIMARY KEY constraint. For example, the ProductID column of the Products table is a primary key for the table.
Referential Integrity
Referential integrity ensures the relationships between tables remain preserved as data is inserted, deleted, and modified. You can apply referential integrity using a FOREIGN KEY constraint. The ProductID column of the Order Details table has a foreign key constraint applied referencing the Orders table. The constraint prevents an Order Detail record from using a ProductID that does not exist in the database. Also, you cannot remove a row from the Products table if an order detail references the ProductID of the row.
Entity and referential integrity together form key integrity.
Domain Integrity
Domain integrity ensures the data values inside a database follow defined rules for values, range, and format. A database can enforce these rules using a variety of techniques, including CHECK constraints, UNIQUE constraints, and DEFAULT constraints. These are the constraints we will cover in this article, but be aware there are other options available to enforce domain integrity. Even the selection of the data type for a column enforces domain integrity to some extent. For instance, the selection of datetime for a column data type is more restrictive than a free format varchar field.
The following list gives a sampling of domain integrity constraints.
A product name cannot be NULL.
A product name must be unique.
The date of an order must not be in the future.
The product quantity in an order must be greater than zero.
Unique Constraints
As we have already discussed, a unique constraint uses an index to ensure a column (or set of columns) contains no duplicate values. By creating a unique constraint, instead of just a unique index, you are telling the database you really want to enforce a rule, and are not just providing an index for query optimization. The database will not allow someone to drop the index without first dropping the constraint.
From a SQL point of view, there are three methods available to add a unique constraint to a table. The first method is to create the constraint inside of CREATE TABLE as a column constraint. A column constraint applies to only a single column. The following SQL will create a unique constraint on a new table: Products_2.
CREATE TABLE Products_2
(
ProductID int PRIMARY KEY,
ProductName nvarchar (40) Constraint IX_ProductName UNIQUE
)
This command will actually create two unique indexes. One is the unique, clustered index given by default to the primary key of a table. The second is the unique index using the ProductName column as a key and enforcing our constraint.
A different syntax allows you to create a table constraint. Unlike a column constraint, a table constraint is able to enforce a rule across multiple columns. A table constraint is a separate element in the CREATE TABLE command. We will see an example of using multiple columns when we build a special CHECK constraint later in the article. Notice there is now a comma after the ProductName column definition.
CREATE TABLE Products_2
(
ProductID int PRIMARY KEY,
ProductName nvarchar (40),
CONSTRAINT IX_ProductName UNIQUE(ProductName)
)
The final way to create a constraint via SQL is to add a constraint to an existing table using the ALTER TABLE command, as shown in the following command:
CREATE TABLE Products_2
(
ProductID int PRIMARY KEY,
ProductName nvarchar (40)
)
ALTER TABLE Products_2
ADD CONSTRAINT IX_ProductName UNIQUE (ProductName)
If duplicate data values exist in the table when the ALTER TABLE command runs, you can expect an error message similr to the following:
Server: Msg 1505, Level 16, State 1, Line 1
CREATE UNIQUE INDEX terminated because a duplicate key was found for index ID 2.
Most significant primary key is 'Hamburger'.
Server: Msg 1750, Level 16, State 1, Line 1
Could not create constraint. See previous errors.
The statement has been terminated.
Check Constraints
Check constraints contain an expression the database will evaluate when you modify or insert a row. If the expression evaluates to false, the database will not save the row. Building a check constraint is similar to building a WHERE clause. You can use many of the same operators (>, <, <=, >=, <>, =) in additional to BETWEEN, IN, LIKE, and NULL. You can also build expressions around AND and OR operators. You can use check constraints to implement business rules, and tighten down the allowed values and formats allowed for a particular column.
We can use the same three techniques we learned earlier to create a check constraint using SQL. The first technique places the constraint after the column definition, as shown below. Note the constraint name is optional for unique and check constraints.
CREATE TABLE Products_2
(
ProductID int PRIMARY KEY,
UnitPrice money CHECK(UnitPrice > 0 AND UnitPrice < 100)
)
In the above example we are restricting values in the UnitPrice column between 0 and 100. Let’s try to insert a value outside of this range with the following SQL.
INSERT INTO Products_2 VALUES(1, 101)
The database will not save the values and should respond with the following error.
Server: Msg 547, Level 16, State 1, Line 1
INSERT statement conflicted with COLUMN CHECK constraint 'CK__Products___UnitP__2739D489'.
The conflict occurred in database 'Northwind', table 'Products_2', column 'UnitPrice'.
The statement has been terminated.
The following sample creates the constraint as a table constraint, separate from the column definitions.
CREATE TABLE Products_2
(
ProductID int PRIMARY KEY,
UnitPrice money,
CONSTRAINT CK_UnitPrice2 CHECK(UnitPrice > 0 AND UnitPrice < 100)
)
Remember, with a table constraint you can reference multiple columns. The constraint in the following example will ensure we have either a telephone number or a fax number for every customer.
CREATE TABLE Customers_2
(
CustomerID int,
Phone varchar(24),
Fax varchar(24),
CONSTRAINT CK_PhoneOrFax
CHECK(Fax IS NOT NULL OR PHONE IS NOT NULL)
)
You can also add check constraints to a table after a table exists using the ALTER TABLE syntax. The following constraint will ensure an employee date of hire is always in the past by using the system function GETTIME.
CREATE TABLE Employees_2
(
EmployeeID int,
HireDate datetime
)
ALTER TABLE Employees_2
ADD CONSTRAINT CK_HireDate CHECK(hiredate < GETDATE())
Check Constraints and Existing Values
As with UNIQUE constraints, adding a CHECK constraint after a table is populated runs a chance of failure, because the database will check existing data for conformance. This is not optional behavior with a unique constraint, but it is possible to avoid the conformance test when adding a CHECK constraint using WITH NOCHECK syntax in SQL.
CREATE TABLE Employees_2
(
EmployeeID int,
Salary money
)
INSERT INTO Employees_2 VALUES(1, -1)
ALTER TABLE Employees_2 WITH NOCHECK
ADD CONSTRAINT CK_Salary CHECK(Salary > 0)
Check Constraints and NULL Values
Earlier in this section we mentioned how the database will only stop a data modification when a check restraint returns false. We did not mention, however, how the database allows the modification to take place if the result is logically unknown. A logically unknown expression happens when a NULL value is present in an expression. For example, let’s use the following insert statement on the last table created above.
INSERT INTO Employees_2 (EmployeeID, Salary) VALUES(2, NULL)
Even with the constraint on salary (Salary > 0) in place, the INSERT is successful. A NULL value makes the expression logically unknown. A CHECK constraint will only fail an INSERT or UPDATE if the expression in the constraint explicitly returns false. An expression returning true, or a logically unknown expression will let the command succeed.
Restrictions On Check Constraints
Although check constraints are by far the easiest way to enforce domain integrity in a database, they do have some limitations, namely:
A check constraint cannot reference a different row in a table.
A check constraint cannot reference a column in a different table.
NULL Constraints
Although not a constraint in the strictest definition, the decision to allow NULL values in a column or not is a type of rule enforcement for domain integrity.
Using SQL you can use NULL or NOT NULL on a column definition to explicitly set the nullability of a column. In the following example table, the FirstName column will accept NULL values while LastName always requires a non NULL value. Primary key columns require a NOT NULL setting, and default to this setting if not specified.
CREATE TABLE Employees_2
(
EmployeeID int PRIMARY KEY,
FirstName varchar(50) NULL,
LastName varchar(50) NOT NULL,
)
If you do not explicitly set a column to allow or disallow NULL values, the database uses a number of rules to determine the "nullability" of the column, including current configuration settings on the server. I recommended you always define a column explicitly as NULL or NOT NULL in your scripts to avoid problems when moving between different server environments.
Given the above table definition, the following two INSERT statements can succeed.
INSERT INTO Employees_2 VALUES(1, 'Geddy', 'Lee')
INSERT INTO Employees_2 VALUES(2, NULL, 'Lifeson')
However, the following INSERT statement should fail with the error shown below.
INSERT INTO Employees_2 VALUES(3, 'Neil', NULL)
Server: Msg 515, Level 16, State 2, Line 1
Cannot insert the value NULL into column 'LastName', table 'Northwind.dbo.Employees_2';
column does not allow nulls. INSERT fails.
The statement has been terminated.
You can declare columns in a unique constraint to allow NULL values. However, the constraint checking considers NULL values as equal, so on a single column unique constraint, the database allows only one row to have a NULL value.
Default Constraints
Default constraints apply a value to a column when an INSERT statement does not specify the value for the column. Although default constraints do not enforce a rule like the other constraints we have seen, they do provide the proper values to keep domain integrity in tact. A default can assign a constant value, the value of a system function, or NULL to a column. You can use a default on any column except IDENTITY columns and columns of type timestamp.
The following example demonstrates how to place the default value inline with the column definition. We also mix in some of the other constraints we have seen in this article to show you how you can put everything together.
CREATE TABLE Orders_2
(
OrderID int IDENTITY NOT NULL ,
EmployeeID int NOT NULL ,
OrderDate datetime NULL DEFAULT(GETDATE()),
Freight money NULL DEFAULT (0) CHECK(Freight >= 0),
ShipAddress nvarchar (60) NULL DEFAULT('NO SHIPPING ADDRESS'),
EnteredBy nvarchar (60) NOT NULL DEFAULT(SUSER_SNAME())
)
We can examine the behavior of the defaults with the following INSERT statement, placing values only in the EmployeeID and Frieght fields.
INSERT INTO Orders_2 (EmployeeID, Freight) VALUES(1, NULL)
If we then query the table to see the row we just inserted, we should see the following results.
OrderID:1
EmployeeID:1
OrderDate:2003-01-02
Freight: NULL
ShipAddress: NO SHIPPING ADDRESS
EnteredBy: sa
Notice the Freight column did not receive the default value of 0. Specifying a NULL value is not the equivalent of leaving the column value unspecified, the database does not use the default and NULL is placed in the column instead.
Maintaining Constraints
In this section we will examine how to delete an existing constraint. We will also take a look at a special capability to temporarily disable constraints for special processing scenarios.
Dropping Constraints
First, let’s remove the check on UnitPrice in Product table.
ALTER TABLE Products
DROP CONSTRAINT CK_Products_UnitPrice
If all you need to do is drop a constraint to allow a one time circumvention of the rules enforcement, a better solution is to temporarily disable the constraint, as we explain in the next section.
Disabling Constraints
Special situations often arise in database development where it is convenient to temporarily relax the rules. For example, it is often easier to load initial values into a database one table at a time, without worrying with foreign key constraints and checks until all of the tables have finished loading. After the import is complete, you can turn constraint checking back on and know the database is once again protecting the integrity of the data.
Note: The only constraints you can disable are the FOREIGN KEY constraint, and the CHECK constraint. PRIMARY KEY, UNIQUE, and DEFAULT constraints are always active.
Disabling a constraint using SQL is done through the ALTER TABLE command. The following statements disable the CHECK constraint on the UnitsOnOrder column, and the FOREIGN KEY constraint on the CategoryID column.
ALTER TABLE Products NOCHECK CONSTRAINT CK_UnitsOnOrder
ALTER TABLE Products NOCHECK CONSTRAINT FK_Products_Categories
If you need to disable all of the constraints on a table, manually navigating through the interface or writing a SQL command for each constraint may prove to be a laborious process. There is an easy alternative using the ALL keyword, as shown below:
ALTER TABLE Products NOCHECK CONSTRAINT ALL
You can re-enable just the CK_UnitsOnOrder constraint again with the following statement:
ALTER TABLE Products CHECK CONSTRAINT CK_UnitsOnOrder
When a disabled constraint is re-enabled, the database does not check to ensure any of the existing data meets the constraints. We will touch on this subject shortly. To turn on all constraints for the Products table, use the following command:
ALTER TABLE Products CHECK CONSTRAINT ALL
Manually Checking Constaints
With the ability to disable and re-enable constraints, and the ability to add constraints to a table using the WITH NOCHECK option, you can certainly run into a condition where the referential or domain integrity of your database is compromised. For example, let’s imagine we ran the following INSERT statement after disabling the CK_UnitsOnOrder constraint:
INSERT INTO Products (ProductName, UnitsOnOrder) VALUES('Scott''s Stuffed Shells', -1)
The above insert statement inserts a -1 into the UnitsOnOrder column, a clear violation of the CHECK constraint in place on the column. When we re-enable the constraint, SQL Server will not complain as the data is not checked. Fortunately, SQL Server provides a Database Console Command you can run from any query tool to check all enabled constraints in a database or table. With CK_UnitsOnOrder re-enabled, we can use the following command to check for constraint violations in the Products table.
dbcc checkconstraints(Products)
To check an entire database, omit the parentheses and parameter from the DBCC command. The above command will give the following output and find the violated constraint in the Products table.
Table Constraint Where
Products CK_UnitsOnOrder UnitsOnOrder = '-1'
You can use the information in the DBCC output to track down the offending row.
---Summary------ ---------------- --------------------
Through article we learned how to use various constraints to ensure the data in our database stays intact and matches our expectations. The proper use of constrains is the prevention needed to avoid data integrity problems as your application grows.
Transact-SQL Optimization Tips
Try to restrict the queries result set by using the WHERE clause.
This can results in good performance benefits, because SQL Server will return to client only particular rows, not all rows from the table(s). This can reduce network traffic and boost the overall performance of the query.
*****
Try to restrict the queries result set by returning only the particular columns from the table, not all table's columns.
This can results in good performance benefits, because SQL Server will return to client only particular columns, not all table's columns. This can reduce network traffic and boost the overall performance of the query.
*****
Use views and stored procedures instead of heavy-duty queries.
This can reduce network traffic, because your client will send to server only stored procedure or view name (perhaps with some parameters) instead of large heavy-duty queries text. This can be used to facilitate permission management also, because you can restrict user access to table columns they should not see.
*****
Try to avoid using SQL Server cursors, whenever possible.
SQL Server cursors can result in some performance degradation in comparison with select statements. Try to use correlated subquery or derived tables, if you need to perform row-by-row operations.
*****
If you need to return the total table's row count, you can use alternative way instead of SELECT COUNT(*) statement.
Because SELECT COUNT(*) statement make a full table scan to return the total table's row count, it can take very many time for the large table. There is another way to determine the total row count in a table. You can use sysindexes system table, in this case. There is ROWS column in the sysindexes table. This column contains the total row count for each table in your database. So, you can use the following select statement instead of SELECT COUNT(*): SELECT rows FROM sysindexes WHERE id = OBJECT_ID('table_name') AND indid <>Try to use constraints instead of triggers, whenever possible.
Constraints are much more efficient than triggers and can boost performance. So, you should use constraints instead of triggers, whenever possible.
*****
Use table variables instead of temporary tables.
Table variables require less locking and logging resources than temporary tables, so table variables should be used whenever possible. The table variables are available in SQL Server 2000 only.
*****
Try to avoid the HAVING clause, whenever possible.
The HAVING clause is used to restrict the result set returned by the GROUP BY clause. When you use GROUP BY with the HAVING clause, the GROUP BY clause divides the rows into sets of grouped rows and aggregates their values, and then the HAVING clause eliminates undesired aggregated groups. In many cases, you can write your select statement so, that it will contain only WHERE and GROUP BY clauses without HAVING clause. This can improve the performance of your query.
*****
Try to avoid using the DISTINCT clause, whenever possible.
Because using the DISTINCT clause will result in some performance degradation, you should use this clause only when it is necessary.
*****
Include SET NOCOUNT ON statement into your stored procedures to stop the message indicating the number of rows affected by a T-SQL statement.
This can reduce network traffic, because your client will not receive the message indicating the number of rows affected by a T-SQL statement.
*****
Use the select statements with TOP keyword or the SET ROWCOUNT statement, if you need to return only the first n rows.
This can improve performance of your queries, because the smaller result set will be returned. This can also reduce the traffic between the server and the clients.
*****
Use the FAST number_rows table hint if you need to quickly return 'number_rows' rows.
You can quickly get the n rows and can work with them, when the query continues execution and produces its full result set.
*****
Try to use UNION ALL statement instead of UNION, whenever possible.
The UNION ALL statement is much faster than UNION, because UNION ALL statement does not look for duplicate rows, and UNION statement does look for duplicate rows, whether or not they exist.
*****
Do not use optimizer hints in your queries.
Because SQL Server query optimizer is very clever, it is very unlikely that you can optimize your query by using optimizer hints, more often, this will hurt performance.
This can results in good performance benefits, because SQL Server will return to client only particular rows, not all rows from the table(s). This can reduce network traffic and boost the overall performance of the query.
*****
Try to restrict the queries result set by returning only the particular columns from the table, not all table's columns.
This can results in good performance benefits, because SQL Server will return to client only particular columns, not all table's columns. This can reduce network traffic and boost the overall performance of the query.
*****
Use views and stored procedures instead of heavy-duty queries.
This can reduce network traffic, because your client will send to server only stored procedure or view name (perhaps with some parameters) instead of large heavy-duty queries text. This can be used to facilitate permission management also, because you can restrict user access to table columns they should not see.
*****
Try to avoid using SQL Server cursors, whenever possible.
SQL Server cursors can result in some performance degradation in comparison with select statements. Try to use correlated subquery or derived tables, if you need to perform row-by-row operations.
*****
If you need to return the total table's row count, you can use alternative way instead of SELECT COUNT(*) statement.
Because SELECT COUNT(*) statement make a full table scan to return the total table's row count, it can take very many time for the large table. There is another way to determine the total row count in a table. You can use sysindexes system table, in this case. There is ROWS column in the sysindexes table. This column contains the total row count for each table in your database. So, you can use the following select statement instead of SELECT COUNT(*): SELECT rows FROM sysindexes WHERE id = OBJECT_ID('table_name') AND indid <>Try to use constraints instead of triggers, whenever possible.
Constraints are much more efficient than triggers and can boost performance. So, you should use constraints instead of triggers, whenever possible.
*****
Use table variables instead of temporary tables.
Table variables require less locking and logging resources than temporary tables, so table variables should be used whenever possible. The table variables are available in SQL Server 2000 only.
*****
Try to avoid the HAVING clause, whenever possible.
The HAVING clause is used to restrict the result set returned by the GROUP BY clause. When you use GROUP BY with the HAVING clause, the GROUP BY clause divides the rows into sets of grouped rows and aggregates their values, and then the HAVING clause eliminates undesired aggregated groups. In many cases, you can write your select statement so, that it will contain only WHERE and GROUP BY clauses without HAVING clause. This can improve the performance of your query.
*****
Try to avoid using the DISTINCT clause, whenever possible.
Because using the DISTINCT clause will result in some performance degradation, you should use this clause only when it is necessary.
*****
Include SET NOCOUNT ON statement into your stored procedures to stop the message indicating the number of rows affected by a T-SQL statement.
This can reduce network traffic, because your client will not receive the message indicating the number of rows affected by a T-SQL statement.
*****
Use the select statements with TOP keyword or the SET ROWCOUNT statement, if you need to return only the first n rows.
This can improve performance of your queries, because the smaller result set will be returned. This can also reduce the traffic between the server and the clients.
*****
Use the FAST number_rows table hint if you need to quickly return 'number_rows' rows.
You can quickly get the n rows and can work with them, when the query continues execution and produces its full result set.
*****
Try to use UNION ALL statement instead of UNION, whenever possible.
The UNION ALL statement is much faster than UNION, because UNION ALL statement does not look for duplicate rows, and UNION statement does look for duplicate rows, whether or not they exist.
*****
Do not use optimizer hints in your queries.
Because SQL Server query optimizer is very clever, it is very unlikely that you can optimize your query by using optimizer hints, more often, this will hurt performance.
Wednesday, April 22, 2009
Diff Between Stored Procedure and Finction
SQL Server user-defined functions and stored procedures offer similar functionality. Both allow we to create bundles of SQL statements that are stored on the server for future use. This offers we a tremendous efficiency benefit, as we save programming time by:
- Reusing code from one program to another, cutting down on program development time
- Hiding the SQL details, allowing database developers to worry about SQL and application developers to deal only in higher-level languages
- Centralize maintenance, allowing you to make business logic changes in a single place that automatically affect all dependent applications
- Stored procedures are called independently, using the EXEC command, while functions are called from within another SQL statement.
- Stored procedure allow you to enhance application security by granting users and applications permission to use stored procedures, rather than permission to access the underlying tables. Stored procedures provide the ability to restrict user actions at a much more granular level than standard SQL Server permissions. For example, if you have an inventory table that cashiers must update each time an item is sold (to decrement the inventory for that item by 1 unit), you can grant cashiers permission to use a decrement_item stored procedure, rather than allowing them to make arbitrary changes to the inventory table.
- Functions must always return a value (either a scalar value or a table). Stored procedures may return a scalar value, a table value or nothing at all.
SQL Server Stored Procedures
Microsoft SQL Server provides the stored procedure mechanism to simplify the database development process by grouping Transact-SQL statements into manageable blocks.
We can simplify this process through the use of a stored procedure. Let's create a procedure called sp_GetInventory that retrieves the inventory levels for a given warehouse. Here's the SQL code:
Benefits of Stored Procedures
Why should we stored procedures? Let's take a look at the key benefits of this technology:- Precompiled execution. SQL Server compiles each stored procedure once and then reutilizes the execution plan. This results in tremendous performance boosts when stored procedures are called repeatedly.
- Reduced client/server traffic. If network bandwidth is a concern in your environment, you'll be happy to learn that stored procedures can reduce long SQL queries to a single line that is transmitted over the wire.
- Efficient reuse of code and programming abstraction. Stored procedures can be used by multiple users and client programs. If you utilize them in a planned manner, you'll find the development cycle takes less time.
- Enhanced security controls. You can grant users permission to execute a stored procedure independently of underlying table permissions.
Structure
Stored procedures are extremely similar to the constructs seen in other programming languages. They accept data in the form of input parameters that are specified at execution time. These input parameters (if implemented) are utilized in the execution of a series of statements that produce some result. This result is returned to the calling environment through the use of a recordset, output parameters and a return code. That may sound like a mouthful, but you'll find that stored procedures are actually quite simple.Example
Let's take a look at a practical example. Assume we have the table shown at the bottom of this page, named Inventory. This information is updated in real-time and warehouse managers are constantly checking the levels of products stored at their warehouse and available for shipment. In the past, each manager would run queries similar to the following:SELECT Product, QuantityThis resulted in very inefficient performance at the SQL Server. Each time a warehouse manager executed the query, the database server was forced to recompile the query and execute it from scratch. It also required the warehouse manager to have knowledge of SQL and appropriate permissions to access the table information.
FROM Inventory
WHERE Warehouse = 'FL'
We can simplify this process through the use of a stored procedure. Let's create a procedure called sp_GetInventory that retrieves the inventory levels for a given warehouse. Here's the SQL code:
CREATE PROCEDURE sp_GetInventoryOur Florida warehouse manager can then access inventory levels by issuing the command
@location varchar(10)
AS
SELECT Product, Quantity
FROM Inventory
WHERE Warehouse = @location
EXECUTE sp_GetInventory 'FL'The New York warehouse manager can use the same stored procedure to access that area's inventory.
EXECUTE sp_GetInventory 'NY'Granted, this is a simple example, but the benefits of abstraction can be seen here. The warehouse manager does not need to understand SQL or the inner workings of the procedure. From a performance perspective, the stored procedure will work wonders. The SQL Sever creates an execution plan once and then reutilizes it by plugging in the appropriate parameters at execution time.
Diff Between Truncate & Delete
Both these commands can be used to remove data from a table. However, there are significant differences between the two. Truncate command is faster because it does not have the resource overhead of logging the deletions in the log. It also acquires less number of locks and the only record of the truncation is the page deallocation. Thus the records removed using this command cannot be restored. Command wise, you cannot specify a where clause for this command. Besides the advantage of being faster (due to minimal logging), another advantage in the case of SQL Server is that it re-sets the IDENTITY value back to the original value and the deallocated pages can be re-used. Besides the limitation of not being able to restore the data, another limitation is that it cannot be used for tables that are involved in replication (or log shipping in the case of SQL Server) and it cannot be used on the tables that are referenced by foreign keys. In addition, this command does not fire the triggers.
Delete command on the other hand logs each and every row in the log. It consumes more database resources and locks. However, the data can be restored easily, you can specify a where clause and the triggers get honored. In SQL Server, you would need to re-seed the identity value using the DBCC CHECKIDENT command once you are done with the delete statement.
TRUNCATE is typically used in data warehousing applications for removal of the data in the staging tables while doing the loads.
In the case of SQL Server, you can rollback a truncate command in SQL Server.
Temporary Tables
Usage of temporary tables in MS SQL Server is more developer friendly and they are widely used in development. Local temporary tables are visible only in current session while global temporary tables are visible across all sessions.
Local Temporary tables:
They are created using same syntax as CREATE TABLE except table name is preceded by ‘#’ sign. When table is preceded by single ‘#’ sign, it is defined as local temporary table and its scope is limited to session in which it is created.
Open one session SSMS (Management Studio) and create a temporary table as shown below.
CREATE TABLE #TEMP
(
COL1 INT,
COL2 VARCHAR(30),
COL3 DATETIME DEFAULT GETDATE()
)
GO
Upon successful execution of above command, MS SQL Server creates table in tempdb database. One cannot create another temporary table with the same name in the same session. It will give an error but table with the same name can be created from another session. To do this, open another session from SSMS and issue same command again. It will successfully create new temporary table for that session.
In order to identify which table is created by which user (in case of same temporary table name), SQL Server suffixes it with the number. This is very common scenario when temporary table is defined in the stored procedure and procedure is getting executed by different users simultaneously. Since we have created temporary table with the same name from two different sessions, we should see two entries in tempdb database. From another session or any of the current session, issue following command. Output is displayed after select statement.
USE TEMPDB
GO
SELECT Table_Catalog, Table_Name FROM information_schema.tables
WHERE table_name like ‘%TEMP%’
GO
Table_Catalog Table_Name
————- ———-
tempdb #TEMP________0000000001F7
tempdb #TEMP________0000000001F9
Now create some data from the session in which temporary table (#temp) is created.
INSERT INTO #TEMP(COL1, COL2) VALUES(1,’Decipher’);
INSERT INTO #TEMP(COL1, COL2) VALUES(2,’Information’);
INSERT INTO #TEMP(COL1, COL2) VALUES(3,’systems’);
Selecting data from temporary table will give following results.
COL1 COL2 COL3
———– —————————— ———————–
1 Decipher 2007-03-27 19:39:56.727
2 Information 2007-03-27 19:39:56.727
3 systems 2007-03-27 19:39:56.727
This data is not visible from another session since we are using local temporary table. We can verify it by connecting to another session and querying the #temp table. Local temporary tables are dropped when session which created the table is ended, if one has not dropped it explicitly.
Also, please do note that if you are creating temp tables in a stored procedure, the scope for the existence of those temporary tables is only the procedure execution. The temp tables automatically get dropped once the procedure execution is over (they can be explicitly dropped as well). Once the procedure execution is over, those temp tables will not be accessible from within that session. Example:
create proc test
as
begin
set nocount on
create table #temp (col1 int)
insert into #temp values (1)
end
go
exec test
select * from #temp
Msg 208, Level 16, State 0, Line 2
Invalid object name ‘#temp’.
Global Temporary tables:
Syntax difference between global and local temporary table is of an extra ‘#’ sign. Global temporary tables are preceded with two ‘#’ (##) sign. Following is the definition. In contrast of local temporary tables, global temporary tables are visible across entire instance.
CREATE TABLE ##TEMP_GLOBAL
(
COL1 INT,
COL2 VARCHAR(30),
COL3 DATETIME DEFAULT GETDATE()
)
GO
Execute above statement to create global temporary table. You can verify it by checking the tempdb database. As global temporary tables are available across the instance, SQL Server doesn’t suffix it with the number. Following is the output of query ran against tempdb.
USE TEMPDB
GO
SELECT Table_Catalog, Table_Name FROM information_schema.tables
WHERE table_name like ‘##TEMP%’
GO
Table_Catalog Table_Name
————- ———-
tempdb ##TEMP_GLOBAL
There will be only single instance of global temporary table. Attempt of creating global temporary table with the same name from any other session will result into an error.
Create some data in one of the session where temporary table (##temp_global) is created.
INSERT INTO ##TEMP_GLOBAL(COL1, COL2) VALUES(1,’Decipher’);
INSERT INTO ##TEMP_GLOBAL(COL1, COL2) VALUES(2,’Information’);
INSERT INTO ##TEMP_GLOBAL(COL1, COL2) VALUES(3,’systems’);
Connect to other existing session or open new session. Execute following statement and you will notice that global temporary table is available along with the data from other session as well.
COL1 COL2 COL3
———– —————————— ———————–
1 Decipher 2007-03-28 09:52:34.310
2 Information 2007-03-28 09:52:34.310
3 systems 2007-03-28 09:52:34.310
Global temporary tables are dropped when last session accessing the tables is closed. It is always good practice to drop the temporary tables in the same scope, once we are done with it. This will help us in avoiding creation error when same connection from the connection pool is used by different processes which access temporary tables.
Global temporary tables can be used in data warehousing application where one session performs the ETL and populate the global temporary tables and other sessions read from the table, specific data and process it.
A possible replacement for temp tables is a table variable.
Following are the key points when temporary tables are involved.
• Temporary tables can be defined as local or global temporary tables.
• Local temporary tables are available to session in which they are created. If another session creates the table with the same name, it will be different copy of the table in tempdb database.
• Global temporary tables are available across the instance. Any user from any session can access it.
• It is best practice to drop the temporary table when related work is finished rather than relying on connection to end for the cleanup.
• Table variables can be used instead of temporary tables for performance reasons and when dealing with smaller sub-sets.
• When used in the procedure,function or trigger, its scope ends once execution is completed.
Make Non identity column to an identity column in SQL Server
At times, we run into a situation where we have to convert an existing non identity column to an identity column. Let us assume that currently there is logic in place to generate running numbers for the primary key column of the table. We want to convert it to an identity column in order to get database generated value for the primary key and thus avoiding an extra logic to generate running number. In this blog post, we will show you how we can achieve it. Following is the table structure to demonstrate the example. Create the table structure and populate it with data.
CREATE TABLE dbo.Invoice
(
INVOICE_NUMBER INT NOT NULL,
INVOICE_DATE DATETIME NOT NULL,
CLIENT_ID INT NOT NULL,
INVOICE_AMT NUMERIC(9,2) DEFAULT 0 NOT NULL,
PAID_FLAG TINYINT DEFAULT 0 NOT NULL, — 0 Not paid/ 1 paid
CONSTRAINT PK_INVOICE PRIMARY KEY(INVOICE_NUMBER)
)
– FileGroup clause
;
INSERT INTO INVOICE(Invoice_Number, Invoice_date, client_ID, Invoice_Amt)
VALUES(1,getdate(),101,1100.00);
INSERT INTO INVOICE(Invoice_Number, Invoice_date, client_ID, Invoice_Amt)
VALUES(2,getDate(),102,1100.00);
INSERT INTO INVOICE(Invoice_Number, Invoice_date, client_ID, Invoice_Amt)
VALUES(4,getdate(),103,1100.00);
INSERT INTO INVOICE(Invoice_Number, Invoice_date, client_ID, Invoice_Amt)
VALUES(6,getdate(),104,1100.00);
This is how data looks like. It is formatted for better viewing.
Inv# Invoice_Date Client_ID Invoice_Amount Paid_Flag
—- ———— ———- ————– ———
1 2007-02-18 15:25:09.107 101 1100.00 0
2 2007-02-18 15:25:09.107 102 1100.00 0
4 2007-02-18 15:25:09.107 103 1100.00 0
6 2007-02-18 15:25:09.107 104 1100.00 0
Unlike Oracle Sequences, which are separate objects, identity property is attached with the table. Table can contain only one identity column. There is no straight way to alter column to identity column or vice versa (altering identity column to regular column). We need to drop and re-create the column with identity property. This is how we will do it.
Since the invoice_number column is the primary key, we need to drop the primary key constraint first and then drop the column. Also the assumption is that this is a standalone table and doesn’t have any child tables. If there are child tables, then the FK constraints will need to be dropped, updates will need to be made to those child tables as well to update the references to the parent table using a temp table or a table variable to do the co-relation between the old and the new values and then the FK constraints will need to be re-created.
But before dropping the column, we need to make sure that we don’t loose existing data. So we will first save existing data into other table temporarily.
SELECT * INTO TEMP_INVOICE FROM INVOICE
GO
Successful execution of above command will make sure that existing data is saved safely into newly created TEMP_INVOICE table.
Now first we will truncate the data from existing table and we will drop constraint, column and re-create the column with identity property and then add the constraint back.
TRUNCATE TABLE INVOICE
GO
ALTER TABLE INVOICE DROP CONSTRAINT PK_INVOICE
GO
ALTER TABLE INVOICE DROP COLUMN INVOICE_NUMBER
GO
Now we will add column back with identity property attached to it.
ALTER TABLE INVOICE ADD INVOICE_NUMBER INT IDENTITY(1,1) NOT NULL
GO
ALTER TABLE INVOICE ADD CONSTRAINT PK_INVOICE PRIMARY KEY (INVOICE_NUMBER)
GO
Now we will insert data back into INVOICE table from the TEMP_INVOICE. Since we want to retain the existing values, we will have to turn on the IDENTITY_INSERT property on as INVOICE_NUMBER column is created as an identity column.
SET IDENTITY_INSERT INVOICE ON
GO
INSERT INTO INVOICE(Invoice_Number, Invoice_date, client_ID, Invoice_Amt)
SELECT Invoice_Number, Invoice_date, client_ID, Invoice_Amt
FROM Temp_Invoice
GO
SET IDENTITY_INSERT Invoice OFF
GO
Following is the output once we inserted data back into INVOICE table. Output shows that we have retained the existing values of invoice number.
Inv# Invoice_Date Client_ID Invoice_Amount Paid_Flag
—- ———— ———- ————– ———
1 2007-02-18 15:25:09.107 101 1100.00 0
2 2007-02-18 15:25:09.107 102 1100.00 0
4 2007-02-18 15:25:09.107 103 1100.00 0
6 2007-02-18 15:25:09.107 104 1100.00 0
You can add few more records by omitting the invoice_number in the insert statement and see the output. Look for last two records.
INSERT INTO INVOICE(Invoice_date, client_ID, Invoice_Amt) VALUES(getdate(),105,1100.00);
INSERT INTO INVOICE(Invoice_date, client_ID, Invoice_Amt) VALUES(getDate(),106,1100.00);
After adding two more rows, following is the output.
Inv# Invoice_Date Client_ID Invoice_Amount Paid_Flag
—- ———— ———- ————– ———
1 2007-02-18 15:25:09.107 101 1100.00 0
2 2007-02-18 15:25:09.107 102 1100.00 0
4 2007-02-18 15:25:09.107 103 1100.00 0
6 2007-02-18 15:25:09.107 104 1100.00 0
7 2007-02-18 15:43:06.473 105 1100.00 0
8 2007-02-18 15:43:06.473 106 1100.00 0
Last step will be to drop the newly created table which is no longer required as we have successfully put the data back into INVOICE table.
DROP TABLE TEMP_INVOICE
GO
Subscribe to:
Posts (Atom)